
색인(Indexing)
DataFrame pds을 indexing 하기 위한 method로는 loc, iloc, at, iat 네 가지가 있습니다. 아래 예제를 통해 살펴보겠습니다.
iloc, iat은 index를 사용해서 값을 가져오며 loc, at은 key, column명으로 값을 가져오는 것을 알 수 있습니다.
- 하나씩 가져오기

- 한개의 column 가져오기
>> df.loc[:]['Age']
11 45
12 36
13 21
Name: Age, dtype: int64
>> df['Age']
11 45
12 36
13 21
Name: Age, dtype: int64
>> df.Age
11 45
12 36
13 21
Name: Age, dtype: int64
- 두 개 이상의 Column 가져오기
Column label들로 구성된 list를 pds key로 넣어줍니다.
>> df[['Name', 'Gender']][1:3]
Name Gender
12 Judy F
13 Fred M한가지 살펴보면 좋은 점은, 위와 같이 조회했을 때 뒤에 [1:3]은 row 1~2 번째 자리의 값을 가져온다는 뜻입니다.
하지만 아래와 같이 조회하면 [11:13]은 자리가 아닌 index 자체를 뜻하기 때문에 11~13 값을 가진 index를 조회합니다.
>> df.loc[11:13]['State']
11 NY
12 CA
13 PA
Name: State, dtype: object
첨가(Add)
- Add row
>> df.loc[len(df)] = ['Hellen', 'TX', 4, 'F']
Name State Age Gender
11 Tom NY 45 M
12 Judy CA 36 F
13 Fred PA 21 M
3 Hellen TX 4 F
- Add column
>> df['Major'] = ['Eng','Math','Physics','Arts']
Name State Age Gender Major
11 Tom NY 45 M Eng
12 Judy CA 36 F Math
13 Fred PA 21 M Physics
3 Hellen TX 4 F Arts
** lambda를 사용해서 조건에 맞는 컬럼 추가
>> adult = lambda x : '어른' if int(x)>18 else '아이'
>> df['Adult'] = list(map(adult, list(df.Age))); df
Name State Age Gender Major Adult
11 Tom NY 45 M Eng 어른
12 Judy CA 36 F Math 어른
13 Fred PA 21 M Physics 어른
3 Hellen TX 4 F Arts 아이
제거(Remove)
- Remove row
drop() method를 사용합니다. 기존 df값을 변경하고 싶으면 (inplace=True) 매개변수를 사용합니다.

row가 삭제돼서 index가 흐트러졌다면, reset_index를 사용해서 맞출 수 있습니다.
DataFrame.reset_index(drop=True, inplace=False)
- drop : 이전 인덱스를 DataFrame 내에서 삭제할지 여부입니다. True로 설정하지 않으면 아래와 같이 level_0 column이 생성됩니다.
>> df.reset_index(inplace=True); df
level_0 index Name State Age Gender Major Adult
0 0 0 Tom NY 45 M Eng 어른
1 2 2 Hellen TX 4 F Arts 아이
- Remove Column
drop() method를 사용합니다. (axis=1) 을 붙여서 컬럼 제거로 사용합니다.
(inplace=True) 메소드를 사용해서 변경 값을 DataFrame에 바로 적용할 수 있습니다.
>> df.drop('Gender', axis=1, inplace=True)
그 외 다양한 함수들
먼저, 함수들을 사용하기 위해 DataFrame 세팅합니다.
# setting
dic = {'Name': ['Tom','Judy','Fred'],
'State': ['NY','CA','PA'],
'Age': [45,36,21],
'Gender': ['M','F','M']}
df = pd.DataFrame(dic);
df.loc[len(df)] = ['Hellen', 'TX', 4, 'F']
df['Major'] = ['Eng','Math','Physics','Arts']
adult = lambda x : '어른' if int(x)>18 else '아이'
df['Adult'] = list(map(adult, list(df.Age))); df
특정 행/열 골라내기(Reindexing)
>> df.reindex(index=[0,2], columns=['Name','Major'])
Name Major
0 Tom Eng
2 Fred Physics
열 이름(Column Label) 변경하기
newcols = {'Age':'age', 'Major':'major'} # dict
df.rename(columns=newcols, inplace=True)
문자열 변경하기
TX -> Tex, PA->Pen으로 변경됩니다.
>> df.replace(['TX','PA'], ['Tex','Pen'], inplace=True); df
Name State age Gender major
0 Tom NY 45 M Eng
1 Judy CA 36 F Math
2 Fred Pen 21 M Physics
3 Hellen Tex 4 F Arts
숫자 변경하기
pd.to_numeric() 함수를 사용합니다. 대상을 확실히 숫자형으로 지정한 후에 변경하기 위해 downcast를 사용해서 타입을 지정합니다.
>> df['age'] = pd.to_numeric(df['age'], downcast='float')*2; df
Name State age Gender major Adult
0 Tom NY 90.0 M Eng 어른
1 Judy CA 72.0 F Math 어른
2 Fred PA 42.0 M Physics 어른
3 Hellen TX 8.0 F Arts 아이
행/열의 배열 순서 변경하기
>> df = pd.DataFrame(df, index=df.index[::-1], columns=df.columns[::-1])
index/column에 이름 지정하기
>> df.index.name='Index'; df.columns.name='Item'; df
행과 열을 서로 바꾸기(Transpose)
T method를 사용합니다.

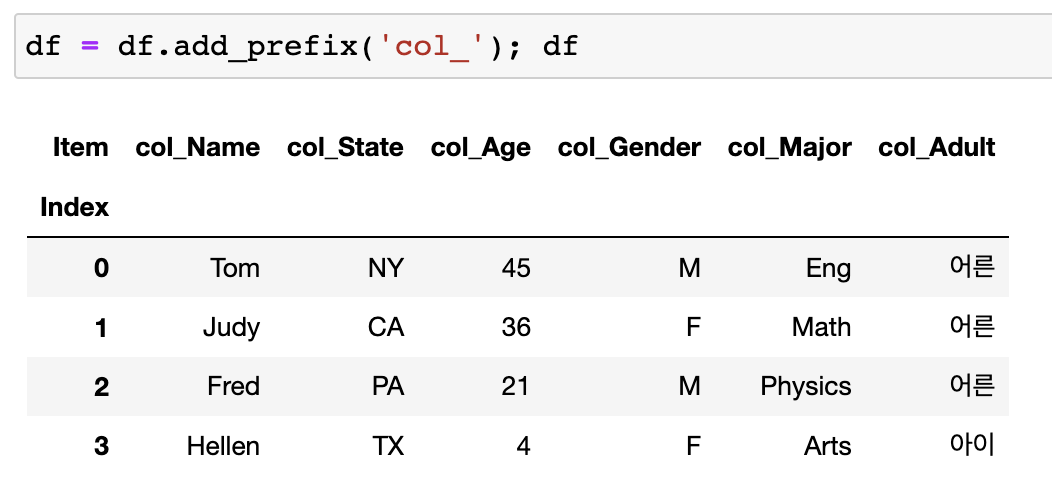
Column Label 앞/뒤에 문자열 덧붙이기(Prefix/Suffix)
References
Python(파이썬)과 Matplotlib, Numpy, Pandas - 양원영, 고병천 외 3명
'프로그래밍 언어' 카테고리의 다른 글
| Python 비동기 Asyncio, coroutine 자세한 내용 (0) | 2023.03.24 |
|---|---|
| Python Pandas - pivot() (0) | 2023.02.06 |
| Python pandas - Series/DataFrame PDS (0) | 2023.01.27 |
| Python NumPy (2) 특수한 Array, reshape, dimension, copy, nan (1) | 2023.01.24 |
| Python Numpy - Array 1D, 2D, 3D (0) | 2023.01.22 |




댓글