목차 LIST
Pivot 테이블이란?
테이블에서 두 개의 column을 각각 row index, column index로 사용하여 데이터를 재정렬 하는 것을 말합니다.
다시 말해, 피벗 테이블은 복잡한 데이터를 요약하고 분석하는데 유용한 테이블입니다. 이것은 마치 데이터를 회전시키거나 "피벗"하듯이 여러 데이터 축을 바탕으로 데이터를 재정렬하는 것을 통해 이해하기 쉬운 형태로 표시합니다.
예를 들어, 온라인 상점의 매출 데이터가 있다고 가정해보겠습니다. 이 데이터에는 "판매일", "상품", "지역", "매출액" 등의 정보가 포함되어 있을 수 있습니다.
이 데이터를 피벗 테이블로 만들면, "지역"을 행으로, "상품"을 열로, "매출액"을 값으로 설정할 수 있습니다. 이렇게 하면 각 지역에서 각 상품의 총 매출을 쉽게 볼 수 있습니다. 또한 이런 방식으로 데이터를 재정렬하면, 어떤 상품이 특정 지역에서 가장 잘 팔리는지 쉽게 알 수 있습니다.
따라서, 피벗 테이블은 크고 복잡한 데이터 세트를 간단하게 요약하고 분석하는 데 도움이 됩니다. 이는 데이터를 보다 쉽게 이해하고, 패턴을 찾아내는 데 유용합니다.
Pandas의 pivot() 함수
pivot()은 Column 기준 데이터 정렬을 위해 사용하는 함수입니다.
DataFrame.pivot(*, index=None, columns=None, values=None)
한 column의 unique한 값들을 index로 하고, 다른 column의 unique한 값들을 (level1)column label로 가진 table을 만들고 싶다면 아래와 같이 사용할 수 있습니다.
import pandas as pd
df = pd.DataFrame(
{'State':['CA', 'NY', 'NY', 'CA', 'PA', 'TX', 'PA', 'TX'],
'Gender':['M', 'M', 'F', 'F', 'F', 'F', 'M', 'M'],
'Income':[21, 17, 23, 32, 25, 14, 29, 18],
'Expense':[15, 21, 28, 13, 21, 18, 25, 15]}
)

pivot 함수를 사용한 결과를 살펴보겠습니다.
Columns에 지정한 State는 level1 column label이 되었고, Income/Expense는 level0 column label이 되었습니다.

이번에는 values를 선택해보겠습니다. 선택한 Income column이 데이터로 사용되는 것을 확인할 수 있습니다.

values를 다른 방식으로 표현할 수도 있습니다.
df.pivot(index='Gender', columns='State', values='Income')
df.pivot(index='Gender', columns='State')['Income']
column이 2개 이상일 때
pandas 홈페이지에 있는 예제로 살펴보겠습니다.
df = pd.DataFrame({
"lev1": [1, 1, 1, 2, 2, 2],
"lev2": [1, 1, 2, 1, 1, 2],
"lev3": [1, 2, 1, 2, 1, 2],
"lev4": [1, 2, 3, 4, 5, 6],
"values": [0, 1, 2, 3, 4, 5]})
Index contains duplicate entries, cannot reshape Error
인덱스/column에 대해 동일한 row가 생기면 발생되는 에러입니다. (Notice that the first two rows are the same for our index and columns arguments.)

어피치가 있는 첫번째, 두번째 row를 확인해보겠습니다. foo,bar컬럼에 대한 값이 동일한 것을 알 수 있습니다.
그렇다면 columns를 bar 대신 baz를 사용하면 에러가 발생하지 않습니다.

생각했던 대로 문제 없이 동작하는 것을 확인할 수 있습니다.
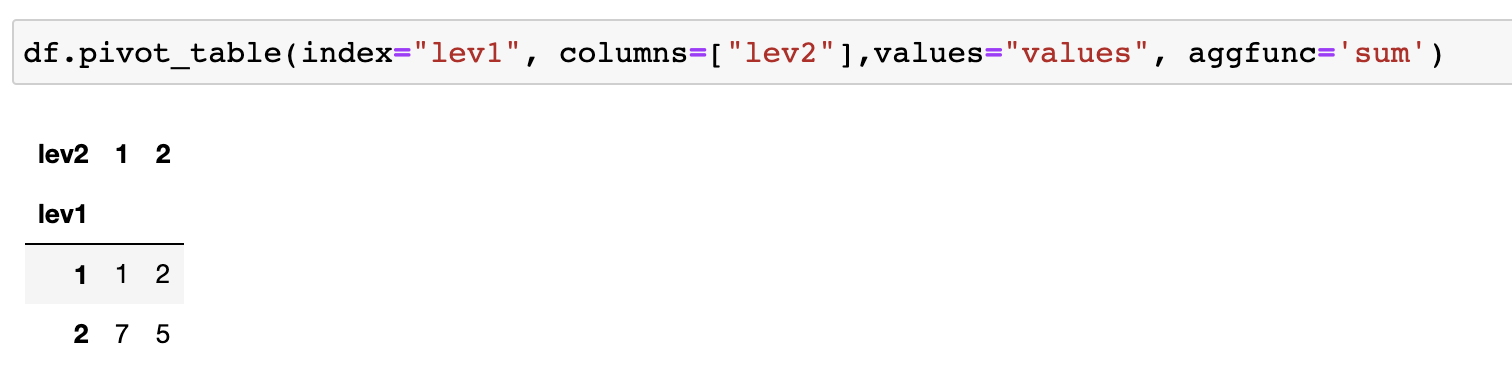
한번 더 살펴보겠습니다. 아래와 같은 table이 있을 때, columns로 lev2, 3을 넣으면 정상적으로 동작하지만 level2만 넣으면 에러가 발생합니다. 여기서 우리는 level2 대신 level3만 단독으로 넣어도 동일한 에러가 발생할 것이라고 생각할 수 있습니다.

해결 방법은 pivot_table() 함수를 사용하는 것입니다. 이때, aggfunc를 넣어줍니다.
References
Python(파이썬)과 Matplotlib, Numpy, Pandas - 양원영, 고병천 외 3명
'프로그래밍 언어' 카테고리의 다른 글
| [스프링부트] 등장 배경, 주요 특징, 핵심 4가지 (0) | 2023.05.30 |
|---|---|
| Python 비동기 Asyncio, coroutine 자세한 내용 (0) | 2023.03.24 |
| Python pandas - DataFrame PDS 함수 (0) | 2023.01.29 |
| Python pandas - Series/DataFrame PDS (0) | 2023.01.27 |
| Python NumPy (2) 특수한 Array, reshape, dimension, copy, nan (1) | 2023.01.24 |




댓글