개요
목차 LIST
What is a State in Flink
Flink Checkpoints : Flink의 내결함성(Fault Tolerance)을 달성하기 위한 매우 중요한 개념이다.
state가 뭔지, state의 유형, 체크포인팅을 사용하여 어떻게 구현되는지에 대해 논의한다.
State(상태)?
스트림 처리 환경에서, 상태를 특정 시점에서의 연산자의 스냅샷 으로 간주할 수 있다.
과거의 입력과 이벤트에 대한 정보를 기억하고, 미래의 출력을 결정하는데 사용될 수 있다. 시스템의 상태는 특정 시점까지 애플리케이션에서 발생한 모든 일을 알고 있다.
상태는 개별 요소(individual elements)나 이벤트 처리 동안 데이터를 저장할 수 있으며, 저장된 상태 또는 데이터의 스냅샷은 애플리케이션을 복구 및 재시작하거나, 머신러닝 모델을 훈련하는 등 다양한 방식으로 사용될 수 있다.
저장된 상태는 다음과 같은 방법으로 사용할 수 있다.
1. 애플리케이션에서 지금까지 발생한 특정 이벤트 패턴을 검색할 때 : State는 지금까지 만난 이벤트의 순서를 저장하기 때문에, 패턴 검색이 가능하다.
2. 머신러닝 모델에서 널리 사용 : 머신러닝에서는 단일 데이터 셋에 대해 여러 번의 변환 반복을 수행한다. (입력 데이터셋 → 변환 1 - > 변환 2 → 변환 3)
머신러닝 모델을 훈련할 때 여러 번의 변환(iteration)을 반복적으로 수행하는데, 이 때 각 변환에서 모델의 매개변수(parameters)가 업데이트된다.
상태는 이러한 반복 과정에서 현재까지의 모델 매개변수를 저장하고 유지하는 역할을 한다. 즉, 훈련이 진행되는 동안 상태는 최신 모델 매개변수를 저장하여, 이후의 변환에서도 이를 사용할 수 있도록 함
3. 과거 데이터를 관리해야 할 때 사용 : 모든 상태를 남기기 때문에 과거 데이터를 확인하기 쉽다.
4. ✔️ (가장 중요) 체크포인팅을 통해 시스템의 내결함성을 달성하는 것 : 저장된 State를 사용하여 노드 장애가 발생했을 때 복구할 수 있다.
장애가 발생했을 때 애플리케이션의 상태가 저장되어 있다면 시스템이 손상된 동일한 체크포인트에서 처리를 정확히 재개할 수 있다.
5. ✔️ 작업을 Rescaling 할 때 사용
Flink는 대규모 병렬 분산 시스템이며, 동일한 연산자가 다른 클러스터의 노드에서 다른 데이터 세트를 병렬로 실행한다. 작업을 리스케일링해야 할 때. 즉, 작업에서 병렬 연산자 인스턴스의 수를 늘리는 상황일 때
만약, 현재 3개의 연산자 인스턴스가 다른 노드에서 실행되고 있고 5개의 인스턴스로 확장하려는 상황이다. 3개의 연산자 인스턴스는 각자의 상태를 유지하고 있으며, 동일한 상태가 HDFS와 같은 영구 저장소에 저장된다.
Rescale 요청을 전달하면, Flink는 HDFS에서 저장된 상태를 가져와 새로운 5개의 연산자 인스턴스에 다시 배포한다.
6. 무상태 변환을 상태 저장 변환으로 만드는 데 사용
상태 객체들을 map, filter, 다른 변환에 통합하여 현재 입력 이전에 온 입력을 추적할 수 있다.
Checkpointing and Barrier Snapshoting
Fault Tolerance & Checkpointing
Apache Flink는 데이터 스트리밍 애플리케이션의 상태를 복구할 수 있는 결함 허용 메커니즘을 제공한다.
이 메커니즘은 실패가 발생하더라도 프로그램 상태를 복구하여 애플리케이션은 실패한 지점에서 정확히 다시 시작될 수 있다. 이 상태 복구 메커니즘이 바로 체크포인팅 이다.
=> 체크포인팅은 상태를 사용하는 개념 (bi-flink에서는 상태를 따로 저장하지 않는데, 체크포인팅을 사용하니 내부적으로 연산자 상태(operator state)를 사용함)
=> 체크포인팅은 애플리케이션의 현재 상태를 주기적으로 스냅샷으로 저장하는 메커니즘
=> 상태는 정보를 저장하는 방식이고, 체크포인팅은 그 상태를 주기적으로 저장하는 메커니즘이다.
체크포인팅의 핵심 원리는 시스템이 분산된 데이터 스트림과 그 데이터 스트림을 처리하는 연산자들의 현재 상태를 정기적으로 기록(스냅샷을 찍음)하여, 문제가 발생했을 때 시스템을 그 시점으로 복구할 수 있도록 한다는 것이다.
Checkpoint Barrier
체크포인팅은 데이터 스트림과 연산자 상태의 빈번한 스냅샷을 찍는 것을 의미한다.
기존의 스냅샷 방식은 정기적인 시간 간격으로 주기적으로 스냅샷을 찍었다. 그러나 이런 방식은 스냅샷 작업이 데이터 스트림 처리와 동시에 진행되는 동안 자원을 많이 소모하여 전체 시스템의 성능을 저하시켰다.
Flink는 이러한 문제를 해결하기 위해 배리어 스냅샷 알고리즘을 사용한다. 스트림 배리어는 flink 분산 스냅샷의 핵심 요소이다.
아래와 같은 데이터스트림이 있다고 가정했을 때, 데이터 스트림에는 flink에 의해 주입된 checkpoint barrier가 있다. 이 배리어가 언제, 어떻게, 어떤 간격으로 주입되는지는 체크포인트 조정 속성에 따라 달라진다.
(Flink Data Stream을 흐르는 데이터들은 크게 세 종류로 나뉜다. Event, Checkpoint Barrier, Watermark)
즉, checkpoint barrier는 처리가 완료된 Event와 완료되지 않은 Event를 나누는 벽이 된다.

배리어는 어떤 기록이나 요소가 현재 스냅샷에 포함될지를 결정한다.

Aligned Checkpoint (= Synchronized Checkpoint)
Checkpoint Barrier는 Source를 시작으로 하여 모든 Task와 subTask들로 전달된다.
Aligned Checkpoint는 한 Task의 모든 SubTask들이 State 업데이트를 마치면 Checkpoint Coordinator에게 State를 모두 갱신했음을 알린다. → Acknowledgement
이렇게 각 Task들이 Checkpoint Barrier에 의해서 State를 갱신하고 Checkpoint Coordinator에게 Acknowledgement를 전달하는 과정을 Checkpoint Alignment 라고 한다.
모든 Task의 Acknowledgement가 마무리되면 State-Backend에 저장되어 있는 상태 정보를 기반으로 Checkpoint가 생성된다.


Unaligned Checkpoint(= Asynchronous Checkpoint)
위와 달리 Checkpoint Coordinator가 Task의 Acknowledgement를 기다리지 않는다. 그래서 Task간의 Sync 없이 Checkpoint가 생성된다.
배리어와 네트워크 버퍼의 데이터를 함께 스냅샷하므로, 배리어 이전의 데이터를 처리할 때까지 기다리지 않아서 지연을 최소화하고 성능을 향상시킨다.
(Aligned checkpoint는 네트워크 버퍼에 있는 데이터를 소진할 때까지 기다리지만, Unaligned checkpoint는 남아 있는 데이터 그대로 포함하여 스냅샷을 찍는다.)
전송 중 데이터(버퍼에 저장된 데이터)를 체크포인트 상태의 일부로 포함한다. 따라서, 체크포인트 시간은 현재 처리량과 무관하게 된다.
백프레셔로 인해 체크포인팅 시간이 매우 길다면 비정렬 체크포인트를 사용해야 한다.
(* backpressure : 시스템이 데이터를 처리하는 속도가 데이터가 들어오는 속도보다 느릴 때 발생하는 현상으로 느린 컴포넌트가 발생시킨 지연이 연쇄적으로 퍼져나가는 현상이다.
데이터가 네트워크 버퍼에 쌓이게 되고, 시스템 전체의 지연 시간을 증가시킨다.)
아래 이미지를 보면, checkpoint barrier가 연산자의 입력 버퍼에 도착하자마자 연산자는 즉시 배리어를 출력 버퍼의 끝에 추가하여 다운스트림 연산자로 전달한다.
연산자는 앞지른(overtaken) 모든 레코드를 비동기적으로 저장하도록 표시하고(초록색), 자신의 상태 스냅샷을 생성한다.
마지막으로 처리를 일시 중지한다. 연산자는 버퍼를 표시하고, 배리어를 전달하여 상태 스냅샷을 만드는 동안 입력 처리를 잠시 중단한다.
(입력 데이터를 잠시 중단해도 배리어 이전의 데이터를 모두 처리할 때까지 기다릴 필요가 없기 때문에 전체 체크포인트 시간이 크게 줄어들어 성능이 향상된다.)

이 과정에서 Checkpoint Barrier보다 새로운 Event가 subtask에 의해서 처리될 수 있으며, Checkpoint 복구가 발생한다면 몇몇 Event는 중복 처리될 가능성이 생긴다.
val ckptCfg = env.getCheckpointConfig
ckptCfg.setExternalizedCheckpointCleanup(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
ckptCfg.setCheckpointStorage({
hadoopEnv.getCheckPointPath
})
ckptCfg.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE) < 얘때문에 중복 처리 안됨
ckptCfg.enableUnalignedCheckpoints(true) <<<<<<<<<<<<<<<<<<<<<<<
참고)
checkpointing_under_backpressure
Flink checkpoint 알아보기 - tistory
상태 백엔드 (state backend)
내부적으로 체크포인트된 상태가 저장되는 방법과 위치, 체크포인트 시 지속되는 방법과 위치를 지정한다.
참고) bi-flink에서는 HashMapStateBackend 를 사용중이며, 해당 내용은 Flink UI > Job > Checkpoints > Configuration에서 확인 가능하다.
Backend의 종류
- MemoryStateBackend : 상태 데이터를 Java 힙 객체로 내부적으로 저장
- FsStateBackend : HDFS와 같은 파일 시스템에 기록
- RocksDBStateBackend : 체크포인트 시 전체 RockDB 데이터베이스가 파일 시스템(HDFS)에 체크포인트 된다.
실패 복구 메커니즘
체크포인트는 매우 가볍고 성능에 큰 영향을 주지 않아 자주 찍을 수 있으며, 체크포인트(스냅샷)를 찍은 후에는 HDFS와 같은 영구 저장소에 저장된다.
실패와 복구 메커니즘의 과정은 다음과 같다.
- Flink는 실패를 감지하면 즉시 데이터 흐름을 중지한다.
- HDFS 저장소에서 가장 최신 성공한 체크포인트를 검색한다.
- 체크포인트에는 두 가지 요소가 저장되는데, 하나는 데이터 스트림 또는 단순 데이터이고 두 번째는 연산자 상태이다.
- 입력 데이터 스트림은 체크포인트에 지정된 지점으로 재설정되고, 연산자는 다시 시작된다.
- 시스템은 실패한 지점에서 다시 시작할 수 있다.
최신 체크포인트 이후 처리된 데이터는 어떻게 하는가?
- 만약, 최신 체크포인트는 5분에 생성됐고, 다음 체크포인트가 10분에 생성될 예정인 상황에서 8분에 시스템 crash가 발생했다.
- 5-8분 사이의 3분 동안의 데이터는 어떻게 될까?
- 데이터 스트림 소스가 최신 체크포인트에 지정된 지점으로 스트림을 되돌린다. 즉, 소스는 스트림을 5분으로 되돌리고 이후 데이터를 재전송한다.
📌 데이터를 재전송하는데 중복이 발생하지 않는 이유는 뭘까?
ㄴ 아래는 flink job id 가 바뀌지 않는 상황을 가정합니다. flink job id 가 변경되면 체크포인트가 없기 때문에 데이터 유실이 발생합니다.
bi-flink의 설정을 살펴보자.
// kafkaSource option
KafkaSource
.builder()
.setProperty("partition.discovery.interval.ms", "3000")
.setProperty("enable.auto.commit", "true") // Flink의 체크포인트와는 독립적으로 이루어짐. default : 5초
.setProperty("request.timeout.ms", "90000")
// checkpointing option
val checkPointInterval = if (argument.env == DeployPhase.PROD) 180000 else 600000 // 3분마다 체크포인트
env.enableCheckpointing(checkPointInterval)
CheckpointingMode.EXACTLY_ONCE // 체크포인트가 성공하면 해당 시점의 Kafka 오프셋도 함께 저장
bi-flink는 체크포인트와 별개로 5초마다 auto commit을 실행한다. 데이터 유실 발생 가능성이 있을까?
참고로, Flink는 체크포인팅 됐을 때 HDFS에 파일을 생성한다. 즉, checkpoint 간격으로 파일이 생성된다.
FileSink.forBulkFormat(
....
)
.withRollingPolicy(OnCheckpointRollingPolicy.build()) // !!!!!!!!!!
...
.build()
아래는 Data loss scenario 이다. auto commit은 5초 간격, checkpoint를 10초간격으로 실행했을 때 데이터 유실이 발생할 수 있다고 말한다.
그림을 보면, 체크포인팅이 실패했을 때, auto commit은 이미 된 상태이기 때문에 이전 파일 생성부터 auto commit 까지의 데이터가 유실된다고 나타내고 있다.
즉, crush가 발생하여 이전 체크포인트로 이동을 해도, auto commit이 되어있기 때문에 2번과 3번 사이의 데이터가 유실된다는 말이다.

(참고: Flink's checkpoint and Kafka auto-commit)
그럼 bi-flink도 kafka auto.commit 시간과 checkpointing 시간이 다르기 때문에 데이터 유실이 발생해야 하는데, 확인 결과 데이터 유실이 발생하지 않았다. 이유는 아래 옵션 때문이다.
CheckpointingMode.EXACTLY_ONCE // 체크포인트가 성공하면 해당 시점의 Kafka 오프셋도 함께 저장위 옵션을 사용하게 되면, crush 가 발생하여 이전 체크포인트로 돌아가게 될 때, kafka offset도 해당 시점으로 돌리게 된다. 그러니 auto commit 된 offset과 별개의 offset을 사용하는 것이다.
위 이미지로 보면 3번에서 1번 시간까지 데이터를 수집하여 파일을 생성하다가, crush 가 발생하면 생성하던 파일을 모두 삭제하고 완전히 3번 시점으로 돌아가서 다시 데이터를 읽으며 파일을 생성한다.
따라서 중복도, 유실도 발생하지 않는다.
하지만, 지금처럼 kafka auto commit 과 CheckpointingMode.EXACTLY_ONCE를 함께 쓰는 것은 권장되지 않는다.
따라서 bi-flink의 kafka auto commit 설정을 false로 하는 것을 검토하려고 한다. CheckpointingMode.EXACTLY_ONCE 옵션을 사용하면 체크포인팅 될 때 kafka offset commit도 함께 이뤄지기 때문이다.
-- 권장 옵션
ckptCfg.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
KafkaSource
.builder()
.setProperty("enable.auto.commit", "false")
아래는 enable.auto.commit 을 false 로 변경했을 때 lag 변화이다.
20:10 기준으로 왼쪽은 5초마다 auto commit이 되고있기 때문에 lag 이 거의 발생하지 않는다. 하지만 commit 만 됐을 뿐 실제 데이터가 처리된 것은 아니다.
20:10 기준으로 오른쪽은 checkpoint 가 완료되어 파일이 생성된 다음 commit 을 한 상황이며, 실제 데이터가 처리된 것을 나타낸다.

Incremental Checkpointing
테라바이트, 페타바이트의 데이터를 실시간으로 처리하게 된다면 상태(state)도 매우 큰 크기가 되어 기가바이트 단위가 될 수 있다.
체크포인트는 가볍지만 이렇게 큰 데이터셋에서 체크포인트를 생성하는 것은 느리고 자원을 많이 소모하는 작업이라 flink 1.3 부터 증분 체크포인트(incremental checkpointing)가 도입되었다.
증분 체크포인팅은 각 체크포인트 간의 차이점, 즉 델타만 유지하며, 마지막 완료된 체크포인트와 현재 애플리케이션 상태 간의 델타만 저장한다.
증분 체크포인팅은 상태가 매우 클 때 상당한 성능 향상을 제공할 수 있다. 테라바이트 단위의 상태를 생성하는 애플리케이션에서 체크포인팅 시간은 3분에서 30초로 줄어들었다.
증분 체크포인팅을 사용하려면 RocksDB와 같은 상태 백엔드를 사용해야 한다.

Types of States
Flink의 상태 추상화를 어떻게 사용하는가
Flink에는 두 가지 기본적인 상태가 있다 : 키 상태(Keyed State), 연산자 상태(Operator State)
1. 연산자 상태 (Oprator State)
연산자 상태는 하나의 병렬 인스턴스에 바인딩된다. 여러 인스턴스의 연산자가 서로 다른 노드에서 병렬로 실행되고 있기 때문에 각 인스턴스는 자체 연산자 상태를 가지고 있다.
데이터 로컬리티를 위해 flink는 연산자의 상태를 작업을 실행하는 동안 작업을 실행하는 노드에 저장하기 때문에 모든 인스턴스는 자체 로컬 상태를 가지게 된다.
2. 키 상태
키 스트림에 적용되는 연산자에 의해서만 생성될 수 있다. 키 마다 하나의 상태가 저장된다. 각 키마다 연산자 상태가 있는 것처럼 생각할 수 있다.
만약 월별 판매 데이터를 저장하는 애플리케이션이 있다면, 각 달의 데이터를 별도로 관리하기 위해 키 상태를 사용할 수 있다.
예)
- 6월의 데이터는 키가 'June'인 상태에 저장
- 7월의 데이터는 키가 'July'인 상태에 저장
- 8월의 데이터는 키가 'August'인 상태에 저장
관리 상태는 Flink 런타임에 의해 제어되는 상태로, 해시 테이블과 같은 데이터 구조로 표현된다. 이 상태는 완전히 Flink에 의해 제어되며, 관리 상태의 예로는 valueState, listState, reducingState 등이 있다.
리스케일링이 발생할 경우 자동으로 상태를 재분배하며, 메모리 관리도 잘된다.
연산자 자체에 의해 제어되는 원시 상태라는 것도 있지만, 관리 상태를 사용하는 것을 권장하므로 앞으로는 관리 상태에 대해서만 다룬다.
Value State Implementation
Managed key state (관리 키 상태)
상태가 장애 내성과 복구를 위해서 사용되기도 하지만, 여러 사용방법이 있다. 그 중 하나는 무상태 변환을 상태가 있는 변환으로 변환하는 것이다. (to convert stateless transformation to state transfortrmations)
원래 상태를 유지하지 않는 무상태 변환 연산자도 Flink의 상태 객체를 사용하여 상태를 유지할 수 있게 만들 수 있다.
예) 무상태 변환 : 입력 스트림의 각 요소에 2를 곱하는 변환
상태 변환 : 입력 스트림의 각 키별로 합계를 유지하는 변환
시작하기 위해, 관리 키 상태 객체들을 구현해야 한다.
valueState, listState, reducingState, aggregationState 가 있으며 하나씩 살펴보자
첫 번째는 valueState이다. 이 상태는 단일 값을 유지하는데 그 값은 우리가 상태를 지울 때까지 업데이트되고 검색될 수 있다.
ValueState<T> : Maintains a single value in it.
아래 예제는 flatMap 변환의 상태를 유지하는 방법이다.
-- 데이터 샘플
-- key : 1 or 2, value : 0~50
2, 1
1, 2
2, 3
1, 4
2, 5
1, 6
2, 7
..키 별로 10개의 입력마다 합계를 계산한다. sum, reduce 등의 상태 있는 연산자를 사용하지 않고 flatMap과 같은 무상태 연산을 사용하여 합계를 계산해야 한다고 제한해보자.
현재 입력 값을 이전 숫자와 합산하려면, 상태 객체를 사용하여 이전 합계를 저장하거나 이전 이벤트의 결과를 저장해야 한다.
List State Implementation
value state가 상태에서 단 하나의 값만 유지하는 반면, list State는 상태에서 요소들의 리스트를 유지한다.
리스트에 element를 추가하고, 검색할 때는 현재 상태에 저장된 모든 element들의 리스트를 검색한다.
Reducing State Implementation
Reducing state는 단일 값을 유지하며, 그 값은 상태에 추가된 모든 값의 집계이다.
따라서 입력된 모든 element의 합계를 미리 계산하고 상태에 저장한다.
아래 예제는 이전 예제들과 유사하지만, reducing state에서는 합계를 계산하기 위해 하나의 Reduce 함수를 정의해야 한다.
그래서 두 가지 상태를 선언한다.
1) 카운트를 저장하기 위한 value state
2) long 타입의 reducing state (10개씩 입력 레코드를 묶어서 그 합계를 계산한다.)
Managed Operator State Implementation
Managed key state(관리 키 상태)에 이어 Managed operator state(관리 연산자 상태)에 대해 알아보자.
각 연산자 인스턴스는 상태를 유지하고 있으며, 키 상태는 keyBy 이후에 작업에만 사용 가능하지만 연산자 상태는 모든 작업에 사용할 수 있다.
또한 연산자 상태는 rescaling에도 사용된다. (키 상태도 rescaling에 사용됨)
flink 작업은 여러 노드에서 병렬로 실행되며, 각 노드는 여러 개의 연산자 인스턴스를 포함할 수 있다.
Rescaling 시, 기존의 연산자 인스턴스들이 유지하고 있던 상태를 새로운 연산자 인스턴스 집합에 올바르게 분배함으로써 데이터 일관성을 유지하고, 중단 없이 작업을 진행할 수 있다.
<상세 과정>
1) 상태 스냅샷 생성 :Rescaling이 시작되면, 현재 각 연산자 인스턴스의 상태가 스냅샷으로 저장된다. 이는 현재 상태를 캡처하는 과정이다.
2) 상태 병합 : 각 연산자 인스턴스의 상태 스냅샷이 병합된다. 예를 들어, 여러 연산자 인스턴스가 각각 유지하고 있던 리스트가 하나의 큰 리스트로 병합된다.
3) 상태 재분배 : 병합된 상태는 새로운 연산자 인스턴스 집합에 고르게 분배된다.
4) 상태 초기화 : 각 새로운 연산자 인스턴스는 할당된 상태를 받아들이고, 이를 초기화하는데 이 과정은 새로운 인스턴스가 해당 상태를 사용하여 작업을 계속 할 수 있도록 설정하는 것이다.
새로운 연산자 인스턴스에 어떻게 분배되는지 확인해보자.
연산자 상태는 리스트 형태로 지원되는데, 이 상태는 직렬화 가능한 객체 리스트로 구성된다. 따라서 Rescaling이 이루어질 때, 이러한 상태는 새로운 병렬 처리 인스턴스들 간에 효과적으로 재분배될 수 있다.
(* 직렬화란 객체를 바이트 스트림으로 변환하여 저장하거나 네트워크를 통해 전송할 수 있게 만드는 과정으로 상태를 디스크에 저장하거나 다른 노드로 전송할 때 필요함)
이러한 객체들은 non-keyed 상태가 재분배될 수 있는 가장 작은 단위이다. non-keyed 상태는 데이터 스트림의 특정 키에 종속되지 않고, 연산자 자체에 종속된다.
상태 접근 방식에 따라 다음과 같은 재분배 방식이 정의된다.
| <재분배 방식> 각 연산자는 상태를 유지하며, 이 상태는 element들의 리스트로 구성된다. HDFS에는 모든 연산자 인스턴스의 상태가 저장되고, 이 상태들은 하나의 단일 리스트로 결합된다. 결과적으로, 전체 상태는 각 인스턴스의 리스트를 논리적으로 연결한 단일 리스트 형태로 저장된다. 1. ✔️ Even-split redistribution(균등 분할 재분배)
 2. Union redistribution(연합 재분배)
|
관리 연산자 상태를 사용하려면, checkpointed function, list checkpointed function,sync function 인터페이스를 함께 구현해야 한다.
checkpointed function 인터페이스는 두 가지 메서드를 재정의하도록 제공한다.
1) snapshotState() : checkpoint가 수행될 때마다 호출된다.
2) initializeState() : 사용자 정의 함수가 초기화될 때마다 호출되며, 함수가 처음 초리화될 때든, 이전 체크포인트에서 복구될 때든 마찬가지이다. 다양한 상태가 초기화되는 장소일 뿐만 아니라 상태 복구 로직이 포함되기도 한다.
sync function 인터페이스는 "invoke" 메서드를 재정의하도록 제공한다.
Broadcast State Implementation
Flink에서 지원되는 세 번째 유형의 상태는 브로드캐스트 상태이다.
브로드캐스트 상태는 일부 데이터를 모든 노드에서 브로드캐스트해야 하는 사례를 지원하기 위해 도입되었다.
브로드캐스트는 하둡에도 분산 캐시(distributed cache)라는 이름으로 다소 유사한 기능이 있다.
예를 들어, 3개의 노드로 구성된 Flink 클러스터가 있으며 각 노드에서 20개의 작업이 실행되고 있다고 가정해보자. 이때 데이터 스트림의 일부 데이터가 필요하면, 해당 데이터에 접근하기 위해 데이터 스트림에서 데이터를 가져와야 한다.
이때, 각 작업이 데이터 스트림의 일부 데이터에 접근할 필요가 있다면, 작업마다 이 데이터 스트림에 대한 별도의 네트워크 전송이 필요하다.
그러나, 이 데이터 스트림을 노드의 로컬 메모리에 저장하고 각 작업이 자신의 머신의 로컬 메모리에서 데이터를 읽을 수 있다면 네트워크 전송 시간을 절약할 수 있는데, 이것이 바로 브로드캐스트 상태이다.
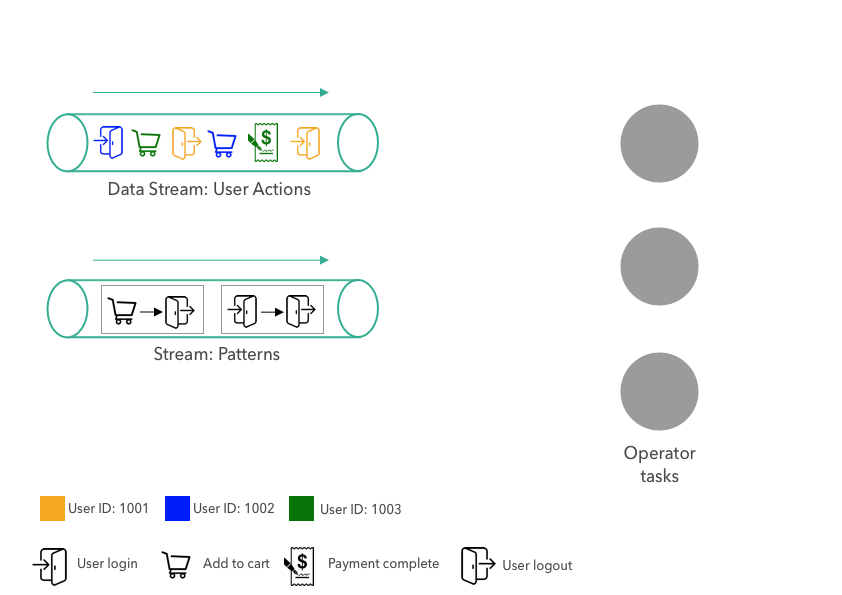
출처 : link
이 방법에서는 데이터 스트림을 브로드캐스트하여 각 노드의 로컬 메모리에 저장하고, 그런 다음 노드의 모든 작업이 자신의 해당 머신에서 로컬로 데이터를 읽는다.
이 브로드캐스트 상태는 새로운 레코드가 이 데이터 스트림에 있을때마다 정기적으로 업데이트된다.
체크포인트 모니터링 방법
몇 개의 체크포인트가 트리거 되었는지,
작업이 여전히 실행 중인 경우 몇 개가 진행 중인지,
몇 개가 완료되었는지,
실패했는지, 복원되었는지 등
체크포인트를 까보자
먼저, Flink UI에서 jobID를 확인한다.
bi-flink의 체크포인트 저장위치는 사용자가 지정한 위치 하위에 다음과 같이 생성된다.
/{job-id}
|
+ --shared/
+ --taskowned/
+ --chk-x/
chk-x 숫자 의미?
체크포인트를 할 때마다 1씩 증가한다. 따라서 아래는 131번째 체크포인트를 했다는 말이고, 10분 후에는 해당 디렉토리가 chk-132로 바뀐다.
_metadata 파일을 열어보자 (참고 : link)
getCheckpointId() : 132
getMasterStates().size() : 0
getOperatorStates().size() : 4
[0].operatorState : OperatorState(operatorID: cbc357ccb763df2852fee8c4fc7d55f2, parallelism: 1, maxParallelism: 128, coordinatorState: 69 bytes, sub task states: 1, total size (bytes): 383)
[1].operatorState : OperatorState(operatorID: ba40499bacce995f15693b1735928377, parallelism: 1, maxParallelism: 128, coordinatorState: (none), sub task states: 1, total size (bytes): 233)
[2].operatorState : OperatorState(operatorID: 570f707193e0fe32f4d86d067aba243b, parallelism: 1, maxParallelism: 128, coordinatorState: (none), sub task states: 1, total size (bytes): 0)
[3].operatorState : OperatorState(operatorID: 3d05135cf7d8f1375d8f655ba9d20255, parallelism: 1, maxParallelism: 128, coordinatorState: (none), sub task states: 1, total size (bytes): 314)
------------------------------- 상세
Number of Operator States: 4
-- 연산자 상세
Operator State [0]: OperatorState(operatorID: cbc357ccb763df2852fee8c4fc7d55f2, parallelism: 1, maxParallelism: 128, coordinatorState: 69 bytes, sub task states: 1, total size (bytes): 383)
Operator ID: cbc357ccb763df2852fee8c4fc7d55f2
Number of Subtask States: 1
-- 데이터 스트림의 현재 위치를 나타내는 오프셋 정보
Subtask State [0]: SubtaskState{operatorStateFromBackend=StateObjectCollection{[OperatorStateHandle{stateNameToPartitionOffsets={SourceReaderState=StateMetaInfo{offsets=[233], distributionMode=SPLIT_DISTRIBUTE}},
-- HDFS 경로와 데이터 크기
delegateStateHandle=ByteStreamStateHandle{handleName='hdfs://...../5634995fe0040de4516896401993a995/chk-132/08e83789-14f3-43a6-ab2b-f808d3cd85cd', dataBytes=314}}]},
operatorStateFromStream=StateObjectCollection{[]}, keyedStateFromBackend=StateObjectCollection{[]}, keyedStateFromStream=StateObjectCollection{[]}, inputChannelState=StateObjectCollection{[]}, resultSubpartitionState=StateObjectCollection{[]}, stateSize=314, checkpointedSize=314}
해당 체크포인트는 4개의 오퍼레이터 상태를 가지고 있다.
참고) Apache Flink에서 오퍼레이터(Operator)는 데이터 스트림을 처리하는 기본 단위로 각 오퍼레이터는 데이터 스트림을 받아 특정 작업을 수행한 후 결과를 다음 오퍼레이터로 전달한다.
map, filter, keyBy, reduce, window 등이 오퍼레이터에 해당된다. 각 오퍼레이터는 병렬로 실행되며, 각 병렬 실행 단위는 태스크(Task)라고 부른다.
코드를 보면 operator는 source, flatMap, sinkTo 3개로 보이는데 왜 4개라고 할까?
// execution plan 출력
val executionPlan = env.getExecutionPlan
LOG.info(executionPlan)
ExecutionPlan 찍어본 결과
1) source 2) flatMap 3) writer 4) committer
HDFS에 파일을 쓸 때, writer , committer 두 작업을 진행한다. writer 는 hdfs에 데이터를 쓰는 작업을 수행하고, committer 는 데이터를 최종적으로 커밋한다.
두 단계는 데이터 무결성을 보장하고 작업 중 발생할 수 있는 오류를 처리하기 위해 나눠져있는데 데이터 기록 중 문제가 발생하면 committer 가 실행되지 않도록 하여 불완전한 데이터가 저장되는 것을 방지할 수 있다.
{
"nodes" : [ {
"id" : 12,
"type" : "Source: {토픽명}",
"pact" : "Data Source", //
"contents" : "Source: {토픽명}",
"parallelism" : 1
}, {
"id" : 13,
"type" : "Flat Map", //
"pact" : "Operator",
"contents" : "Flat Map",
"parallelism" : 1,
"predecessors" : [ {
"id" : 12,
"ship_strategy" : "FORWARD",
"side" : "second"
} ]
}, {
"id" : 15,
"type" : "hdfs://{저장위치}: Writer", //
"pact" : "Operator",
"contents" : "hdfs://{저장위치}: Writer",
"parallelism" : 1,
"predecessors" : [ {
"id" : 13,
"ship_strategy" : "FORWARD",
"side" : "second"
} ]
}, {
"id" : 17,
"type" : "hdfs://{저장위치}: Committer", //
"pact" : "Operator",
"contents" : "hdfs://{저장위치}: Committer",
"parallelism" : 1,
"predecessors" : [ {
"id" : 15,
"ship_strategy" : "FORWARD",
"side" : "second"
} ]
} ]
}
Flink - checkpoint 옵션 및 재시작 전략
목차 LIST Implement Checkpointing in a Flink Program상태를 장애 내성 상태 (fault tolerant)로 만들기 위해서는 Flink가 상태를 체크포인팅해야 한다.체크포인팅은 몇 가지 파라미터를 설정하여 구현할 수 있으
sunrise-min.tistory.com
'데이터 엔지니어링' 카테고리의 다른 글
| Debezium에 대해 알아보자 | 사용 방법 및 MySQL 연동 (0) | 2024.08.19 |
|---|---|
| Flink - checkpoint 옵션 및 재시작 전략 (0) | 2024.08.19 |
| Flink Memory에 대해 알아보자 (0) | 2024.05.21 |
| Flink DataSources 정의 및 구성 요소 (0) | 2024.05.20 |
| Dataflow Windowing : watermark (0) | 2024.05.17 |




댓글