목차
Druid란?
Apache Druid is a high performance real-time analytics database.
대규모 데이터 세트에 대한 빠른 분석을 위해 설계된 실시간 분석 데이터베이스입니다. Druid는 실시간 수집, 빠른 쿼리 성능을 위해 사용되며 빠른 집계가 필요한 동시성이 높은 API 백엔드로 사용됩니다.
Apache Druid는 OLAP 데이터베이스 입니다. OLAP는 Online Analytics Processing의 약자로 사용자가 적재한 데이터를 다양한 방식(다차원)으로 적재하고 분석하도록 도와주는 시스템입니다. 다차원 정보는 기존에 1차원 정보(row단위)를 몇 개의 필드들을 사용해서 지표로 만들어 보여주는 것입니다. 즉, Druid는 다차원 필드인 디멘젼을 사용하여 메트릭을 만들어 보여줍니다.

- Timestamp : 모든 쿼리가 시간 축을 중심으로 이루어지도록 합니다. 만약 시간 축이 없는 데이터를 ingestion하려고 하면 현재 시간을 기준으로 timestamp 컬럼이 채워집니다.
- Dimension : 각 이벤트의 문자열 속성을 담고 있으며, 데이터를 필터링해야 하는 경우에 종종 사용됩니다. 이러한 차원 컬럼들을 축으로 데이터를 slice 할 수 있습니다.
- Metric : 연산에 주로 활용됩니다. 계수, 합산, 평균 등을 집계할 수 있습니다.
아파치 드루이드는 다차원 데이터를 빠른 쿼리로 제공하기 위해 세그먼트 단위로 데이터를 인덱싱하여 저장합니다. 세그먼트를 만드는 것은 time interval 단위이며 쿼리 수행이 아닌 데이터를 적재할 때 함께 인덱싱합니다.
→ 데이터는 분석하기 좋은 형태로 저장됩니다.
Dimension은 filter/group by가 가능한 필드이며 Metric은 수치 데이터로 timestamp에 따라 pre-aggregation/post-aggregation이 가능합니다.
이러한 특징으로 드루이드는 전통적인 데이터베이스에 비해 쿼리시간이 엄청나게 빠르다는 장점을 가집니다. 드루이드는 미리 디멘젼을 지정하면 데이터가 유입될 때마다 인덱싱이 일어나므로 데이터를 빠르게 취합하고 결과를 얻을 수 있습니다.
하지만 드루이드를 정확한 값을 가져와야 할 때 사용하는 것은 적절하지 않습니다. 전체적인 지표의 흐름을 알기 위해 사용하기는 좋지만 정확한 값을 위해 사용하는 것은 권장되지 않습니다. 또한, 데이터를 검색하는데 특화되어 있지 않고 적재된 데이터를 업데이트 할 수 없습니다. 그러므로 업데이트가 빈번히 일어나거나 일부 단어를 검색하는 용도로 사용하는 것 또한 적절하지 않습니다. 또한, 데이터를 조인하여 보는 것도 불가능합니다.
Storage : Segment
Druid는 시간별로 분할된 세그먼트 파일에 인덱스를 저장합니다. 기본 설정으로는 각 시간 간격마다 하나의 세그먼트 파일이 생성됩니다. heavy query load인 상태에서는 드루이드가 잘 작동하기 위해 세그먼트 파일의 크기가 300MB~700MB 내에 있는 것을 권장합니다. 이 범위보다 크면 시간 간격을 더 세분화하거나 데이터를 파티셔닝하고 PartitionSize를 조정하는 것이 좋습니다.
Druid는 시계열 정보를 가진 데이터를 여러 shard로 나누어 분할 저장되며 이를 segment라고 부릅니다. 보통 1개의 세그먼트는 500~1000만개의 row로 이루어집니다. Druid는 시계열 정보로 데이터를 분할하고 데이터 크기가 너무 크거나 작으면 그 외에 다른 컬럼들을 기준으로 추가 분할을 진행하여 segment의 크기를 적절하게 조절합니다.
세그먼트는 Druid의 기본 저장 단위입니다. 클러스터 내 데이터 복제 및 분산은 모두 segment 단위로 이루어집니다. segment 데이터는 변경될 수 없으며 읽기/쓰기 동작 시에 경합이 발생하지 않습니다. 따라서 segment는 데이터를 빠르게 읽기 위한 전용 데이터셋입니다.
또한, 세그먼트 분할은 병렬 처리를 위한 핵심 역할을 가집니다. 여러 세그먼트에 여러 CPU가 동시에 병렬적으로 데이터를 스캔하기 때문에 쿼리 결과를 신속하게 반환할 수 있습니다.
기본적으로 columnar인 세그먼트 파일의 내부 구조를 설명하겠습니다. 각 column 데이터는 별도의 데이터 구조로 배치됩니다. Druid는 각 column을 별도로 저장하여 쿼리에 필요한 column만 검색함으로써 쿼리 시간을 줄입니다. 타임스탬프, dimension 및 metric columns의 세가지 유형이 있습니다.
Timestamp, Metrics columns는 단순합니다. 각 column뒤에는 LZ4로 압축된 정수 또는 부동 소수점 값의 배열이 있습니다. 쿼리가 선택해야 하는 column을 알면 해당 column을 압축 해제하고 추출한 다음 원하는 집계 연산자를 적용하기만 하면 됩니다. 쿼리에 필요하지 않은 column은 스킵합니다.
Dimension(차원) columns는 필터 및 그룹별 작업을 지원하므로 서로 다릅니다. 따라서 세 가지 데이터 구조가 필요합니다.
1) 문자열로 처리되는 value를 정수 ID에 매핑하는 dictionary
1: Dictionary that encodes column values
{
"Justin Bieber": 0,
"Ke$ha": 1
}
2) 1)에서 생성된 dictionary를 사용하여 인코딩된 columns의 value list
2: Column data
[0,
0,
1,
1]
3) column의 고유 값에 대해 해당 값을 포함하는 rows를 나타내는 bitmap
3: Bitmaps - one for each unique value of the column
value="Justin Bieber": [1,1,0,0]
value="Ke$ha": [0,0,1,1]
*Segment 관련 더 많은 내용은 링크 참고
데이터 수집(Ingestion)
druid에 데이터를 로드하는 것을 ingestion 또는 indexing이라 합니다. Druid로 데이터를 수집할 때, Druid는 소스 시스템에서 데이터를 읽고 `세그먼트`라는 데이터 파일에 저장합니다. 일반적으로 세그먼트 파일에는 수만개의 행이 포함됩니다.
대부분의 수집은 Druid MiddleManager process 또는 Indexer process가 소스 데이터를 로드합니다. 유일한 예외는 Hadoop기반 수집인데, YARN에서 Hadoop MapReduce 작업을 사용합니다.
Druid는 batch와 real-time 데이터 수집을 지원합니다.
1) 배치
수집하는 동안(During ingestion,) Druid는 세그먼트를 생성하고 이를 딥 스토리지에 저장합니다. 히스토리컬 노드는 쿼리에 응답하기 위해 세그먼트를 메모리에 로드합니다.
2) 실시간
스트리밍 수집의 경우, 미들 매니저와 인덱서(indexer)는 실시간으로 유입되는 데이터로 바로 쿼리에 응답할 수 있습니다.
실시간 데이터 수집(ingestion)을 위해 real-time Node가 있으며, 이 노드에 저장되는 데이터 스트림 내 이벤트들은 수 초 이내에 Druid 클러스터에 쿼리가 가능한 포맷으로 인덱싱됩니다. (현재 real-time Node는 deprecated 됐으며 kafka indexing service로 전환되었음)
* Ingestion에 대한 자세한 내용은 링크 참고
데이터 Roll-up
Druid는 수집 단계에서 데이터를 롤업하여 디스크에 저장할 raw 데이터의 양을 줄일 수 있습니다. 롤업은 요약이나 사전 집계(pre-aggregation)의 한 종류입니다. 데이터를 롤업하면 저장할 데이터의 크기를 줄이고 row 수를 크게는 몇 배까지 줄일 수 있습니다. 롤업의 효율성에 대한 대가로(trade-off) 개별 이벤트들에 대한 쿼리를 날릴 수 없습니다.
timestamp 단위로 rollup을 진행하면 아래와 같은 결과를 얻을 수 있습니다. 그 시간에 어떤 이벤트가 발생했는지 보다 시간대별 발생횟수가 필요한 상황에는 필요 없는 모든 데이터를 저장하지 않고 count라는 metric컬럼을 사용하여 통합하여 저장합니다.
rollup은 원천 데이터 저장 용량을 최소화시켜 스토리지에 대한 리소스를 절약하며 쿼리 속도를 빠르게 할 수 있습니다.

수집 시 `granularitySpec`.`rollup` 설정으로 롤업을 조절합니다. 롤업은 기본적으로 활성화되어 있습니다. 즉, 드루이드는 `granularitySpec`.`queryGranularity` 설정 기반으로 dimension과 timestamp 같이 동일한 모든 행을 단일 행으로 결합합니다.
"granularitySpec": {
"segmentGranularity": "day",
"queryGranularity": "none",
"intervals": [
"2013-08-31/2013-09-01"
],
"rollup": true
}
롤업을 비활성화하면 Druid는 각 행을 있는 그대로 로드합니다. 비활성화 모드는 롤업 기능을 지원하지 않는 데이터베이스와 유사합니다.
참고)
queryGranularity 옵션에 대해 살펴보면, 이 옵션은 세그먼트 내 타임스탬프 보관의 세부 단위입니다.이 값은 세그먼트 단위와 같거나 더 상세해야 합니다. 쿼리할 수 있는 가장 작은 단위이며 '분' 단위로 저장했다면 분의 배수(5분, 10분, 시간)로도 쿼리가 가능합니다.
여러 단위를 입력할 수 있습니다. 타임스탬프를 자르지 않고 그대로 저장하려면 `None`으로 설정합니다.
: 우리는 시간 단위로 세그먼트를 나누고, queryGranularity도 시간 단위로 지정함(HOUR)
데이터 저장 포맷
데이터를 저장하는 방식은 Druid를 분석 쿼리에 최적화하는 핵심 요소 중 하나입니다.
Druid는 컬럼 기반으로 데이터를 저장합니다. 컬럼 기반으로 데이터를 저장하면 압축률이 높아지므로 스토리지 리소스를 줄일 수 있고 이벤트 스트림을 집계하는 과정에서 특정 컬럼만 사용하기 때문에 CPU 리소스를 줄일 수 있습니다.
Column에는 비슷한 데이터가 모여 있을 확률이 높기 때문에 dictionary encoding과 같은 방법을 사용하여 스트링을 하나의 정수로 매핑할 수 있다면 데이터를 저장하는 리소스를 압축할 수도 있습니다.
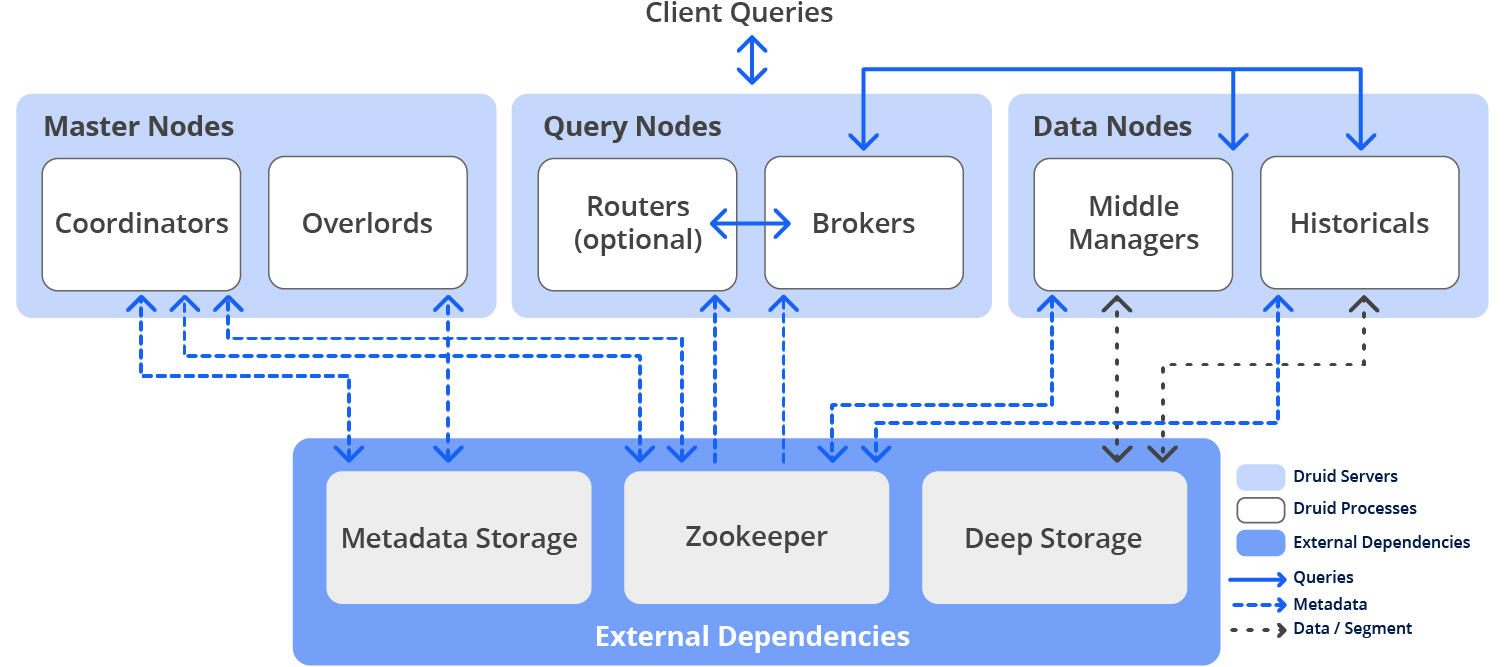
Druid Architecture
<Summary>
들어오는 데이터는 크게 Streaming, Batch Data로 나눌 수 있습니다.
Streaming Data → Kafka(Real-time Nodes)
Batch Data → HDFS(Deep Storage)
HistoricalNodes는 Deep Storage인 HDFS에 저장된 세그먼트를 다운로드합니다. HistoricalNodes에 저장된 세그먼트를 BrokerNodes가 쿼리를 통해 조회합니다.
(아래 그림은 생략된 부분들이 있기 때문에 간단하게 크게 2가지로 데이터가 나뉘는 것만 보면 좋을 것 같습니다)
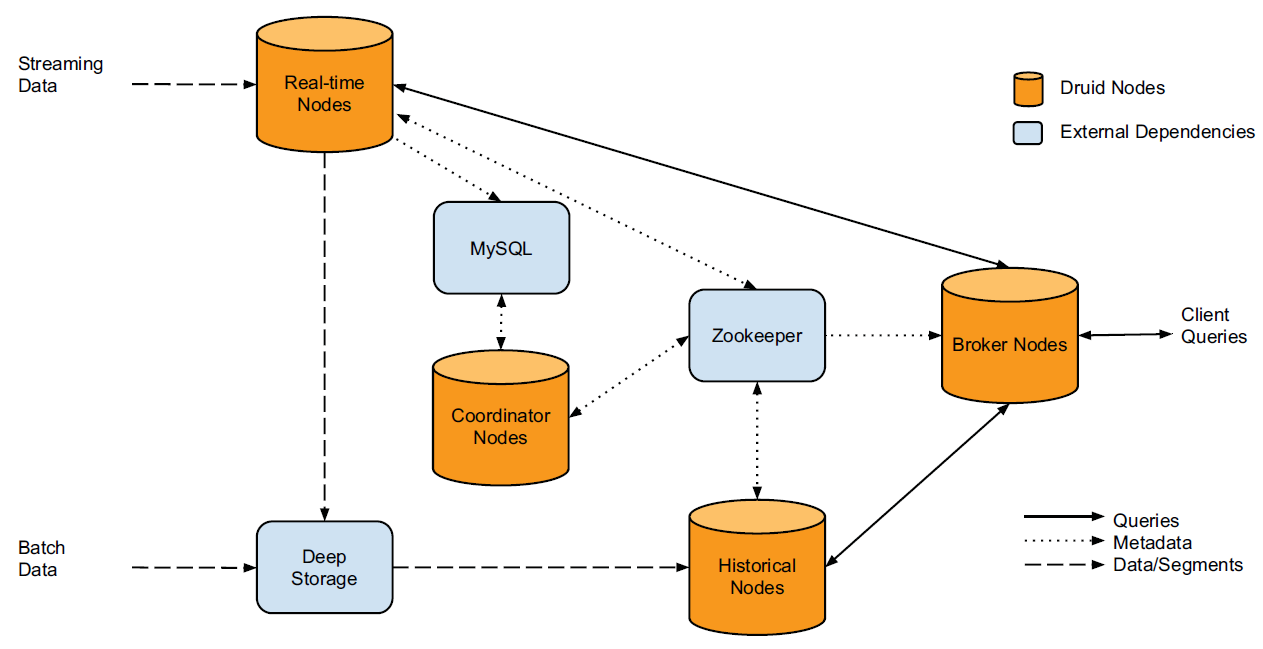
공식 홈페이지에서 제공하는 Druid Architecture는 다음과 같습니다.
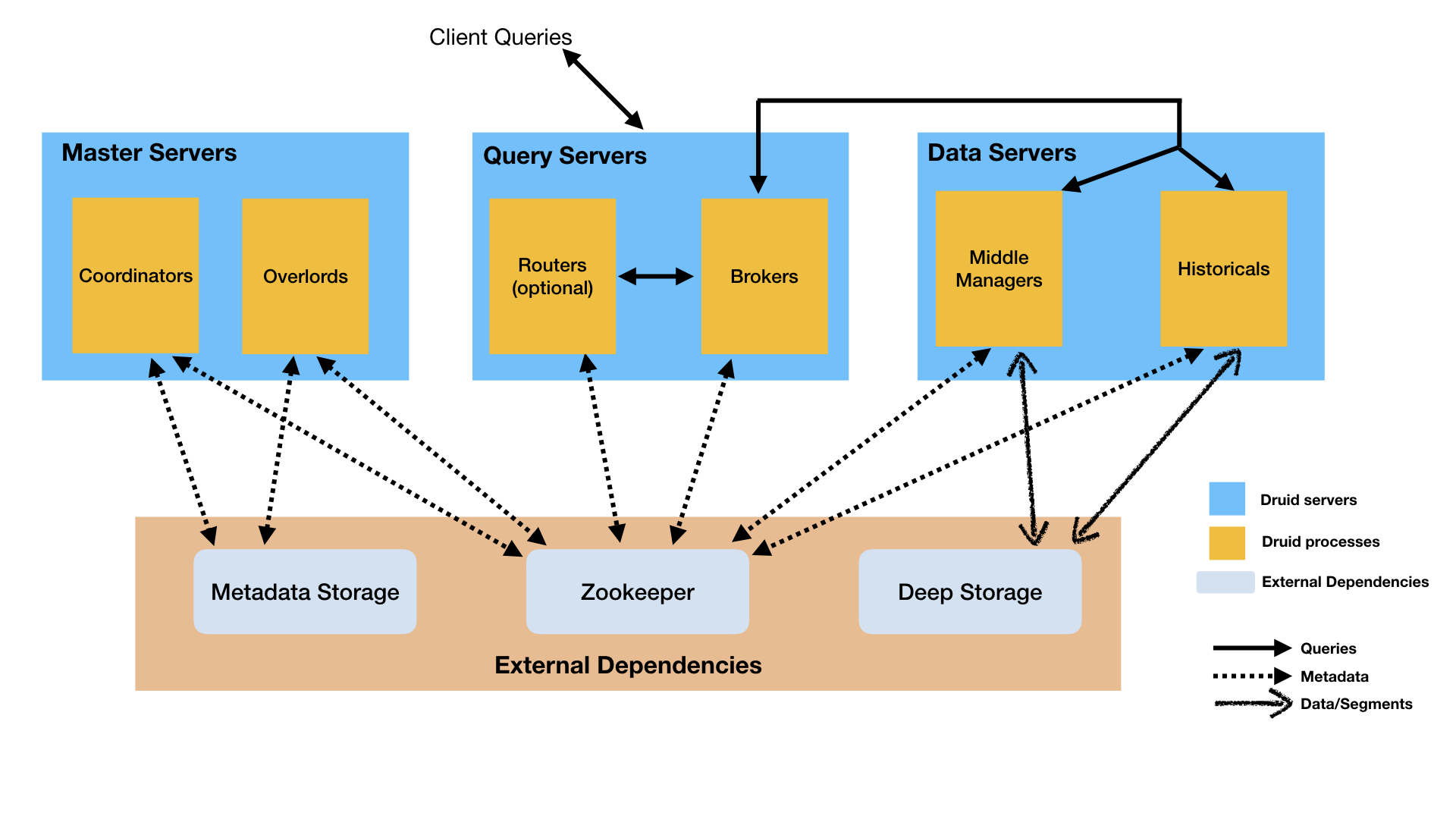
- Coordinator service manages data availability on the cluster.
- Overlord service controls the assignment of data ingestion workloads.
- Broker handles queries from external clients.
- Router services are optional; they route requests to Brokers, Coordinators, and Overlords.
- Historical services store queryable data.
- MiddleManager services ingest data.
<목차>
- Historical:Loading and Serving Segments
- Broker
- Coordinator
- Indexing Service
4.1 Overload
4.2 MiddleManager
4.3 Peons

1. Historical : Loading and Serving Segments
Historical node는 Indexing Service에서 생성된 세그먼트(읽기 전용 데이터 블록)을 로드하고 처리합니다.
각 historical node는 Zookeeper와 지속적인 연결을 유지하고 새로운 segment 들의 경로와 같은 정보를 확인합니다. historical node는 서로 직접 통신하거나 코디네이터 노드와 통신하지 않고 Zookeeper에 의존합니다.
Coordinator node는 새로운 세그먼트를 historical node에 할당하는 역할을 합니다. 할당은 historical node와 연결된 load queue 경로에 임시 Zookeeper 항목을 생성하는 것으로 수행됩니다. (coordinator가 historical node에 세그먼트를 할당하는 자세한 방법은 아래 oordinator에서 다루겠습니다.)
Historical node가 load queue 경로에서 새로운 항목을 발견하면 먼저 로컬 디스크 디렉토리(cache)에서 세그먼트에 대한 정보를 확인합니다. 캐시에 세그먼트에 대한 정보가 없는 경우 historical node는 zookeeper에서 새로운 세그먼트에 대한 메타데이터를 다운로드합니다. 이 메타데이터는 세그먼트가 deep-storage 내에 어디에 있는지, 세그먼트의 압축을 풀고 처리하는 방법에 대한 정보들이 있습니다.
historical node가 세그먼트 처리를 완료하면 node 내에 저장된 세그먼트는 zookeeper에 알려집니다(announced). 이 시점부터 세그먼트는 쿼리에 사용될 수 있습니다.
Loading and Serving Segments From Cache
캐시에서 세그먼트를 로드하고 제공합니다. historical node가 load queue에서 새로운 세그먼트를 감지하면, historical node는 먼저 로컬 디스크에서 구성 가능한 캐시 디렉터리를 확인하여 세그먼트가 이전에 로드되었는지 확인합니다. 로컬 캐시가 이미 있는 경우 historical node는 로컬 디스크에서 세그먼트 binary 파일을 읽고 세그먼트를 로드합니다.
세그먼트 캐시는 historical node가 처음 시작될 때도 활용됩니다. 시작 시 historical node는 캐시 디렉토리를 검색하고 발견된 모든 세그먼트를 즉시 로드하고 제공합니다. 이 기능을 사용하면 historical node가 online이 되는 즉시 쿼리가 가능합니다.
Historical 노드군은 Indexing Service에서 생성된 세그먼트(읽기 전용 데이터 블록)을 로드하고 처리합니다. 이 노드들은 딥 스토리지에서 세그먼트를 다운로드하고 이에 대한 쿼리를 처리합니다. 단순히 Zookeeper의 지시에 따라 세그먼트를 로드, 드롭 처리합니다.
Historical 노드가 쿼리를 처리하는 프로세스는 아래와 같습니다.
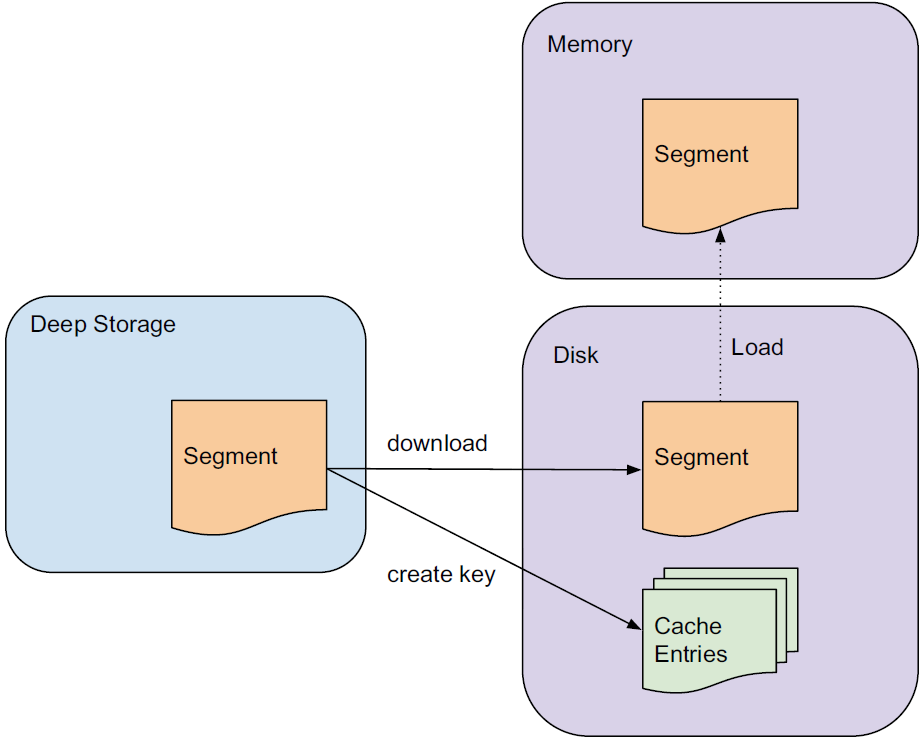
쿼리를 받은 Historical 노드는 먼저 로컬 캐시를 확인합니다. 세그먼트에 관한 정보가 캐싱되어있지 않으면 딥 스토리지에서 해당 세그먼트를 다운로드합니다. 이렇게 되면 해당 세그먼트는 Zookeeper에서 선언되어 쿼리 가능한 대상이 되며, 노드는 이 세그먼트에 대해 요청된 쿼리를 수행합니다.
Historical 노드는 읽기 전용 데이터만을 다루므로 read consistency를 보장할 수 있습니다. 따라서 historical 노드들은 읽기 전용 데이터 블록들을 동시에 스캔, 집계할 수 있습니다.
historical 노드들은 자신들의 온라인 상태와 처리중인 데이터를 Zookeeper에 보고합니다.
2. Broker
Broker는 분산 클러스터를 실행하려는 경우 쿼리를 라우팅하는 노드 입니다. 어떤 노드에 어떤 세그먼트가 있는지에 대한 정보를 Zookeeper의 메타데이터로 확인하고, 올바른 노드에 도달할 수 있도록 쿼리를 라우팅합니다. 그리고 모든 개별 프로세스의 결과 집합을 merge합니다.
대부분의 Druid 쿼리에는 데이터가 요청되는 기간을 나타내는 'interval object'가 포함되어 있습니다. 마찬가지로, 드루이드 세그먼트는 일정 기간의 데이터를 포함하도록 분할되어 있으며 각각의 세그먼트는 클러스터에 분산되어 있습니다.
만약, 각 세그먼트가 특정 요일의 데이터를 포함하는 7개(월~일)의 세그먼트로 나눠져 있다면,
하루 이상의 데이터를 조회하는 쿼리는 둘 이상의 세그먼트를 사용해야 합니다. 이렇게 되면 세그먼트는 여러 노드에 분산되어 있으므로 쿼리도 여러 노드에 분산될 수 있습니다.
Zookeeper에 보고된 메타데이터를 통해 어떤 세그먼트들을 사용해서 쿼리가 가능한지, 이 세그먼트들이 어디에 저장되어 있는 지를 파악합니다. zookeeper의 정보를 기반으로 view of the world(월드뷰)를 작성합니다. zookeeper는 Historical 및 Realtime 노드와 각 노드들이 서비스중인 세그먼트에 대한 정보를 유지관리합니다.
* zookeeper의 모든 데이터소스에 대해 broker node는 세그먼트와 해당 세그먼트를 가진 노드의 timeline을 구축합니다. 특정 데이터 소스 및 간격(interval)에 대한 쿼리가 들어오면 timeline을 확인해서 쿼리에 대한 데이터가 포함된 노드를 검색합니다. 그리고 broker node는 선택한 노드로 쿼리를 전달합니다.
Broker노드는 입력된 쿼리들의 route를 지정함으로써 각 쿼리가 올바른 historical or realtime 노드에 도달되게끔 합니다.
그리고 historical or realtime 노드에서 산출된 결과들을 취합하여 최종 쿼리 결과를 호출자에게 반환합니다.
Caching
broker 노드는 리소스 효율성을 높이기 위해 캐시를 사용합니다.
broker cache는 각 세그먼트의 결과를 저장합니다. 캐시는 각 broker node의 local에 저장하거나 여러 노드에서 공유하기 위해 memcached와 같은 외부 분산 캐시를 사용할 수도 있습니다.
브로커 노드는 쿼리를 수신할 때마다 세그먼트 집합에 쿼리를 매핑합니다. 캐시에 이미 있는 경우 결과를 캐시에서 직접 가져올 수 있으며, 캐시에 없는 경우 브로커 노드가 쿼리를 historical node로 전달합니다. historical node가 결과를 반환하면 broker는 결과를 캐시에 저장합니다.

유입된 쿼리가 여러 세그먼트를 사용해야 할 경우 broker 노드는 캐시에 이미 존재하는 세그먼트들을 우선적으로 확인합니다. 그리고 캐시에 없는 세그먼트들에 대해서 해당 세그먼트가 포함된 historical or realtime 노드로 쿼리를 전달합니다.
historical 노드들이 결과를 반환하면, broker 노드는 이 결과를 나중에 사용할 수 있도록 세그먼트별로 캐시에 저장합니다.
참고로, * 실시간 세그먼트는 캐시되지 않으므로 실시간 데이터 요청은 항상 실시간 노드로 전달됩니다 * 실시간 데이터는 지속적으로 변경되기 때문에 결과를 캐싱하게 되면 신뢰도가 떨어지기 때문입니다.
3. Coordinator
Druid coordinator node는 configuration에 따라 세그먼트를 로드하거나 삭제하기 위해 historical node와 통신합니다. Druid coordinator는 새로운 세그먼트 로드, 오래된 세그먼트 삭제, 세그먼트 복제 관리 및 세그먼트 로드 밸런싱을 담당합니다.
Druid coordinator는 주기적으로 실행되며 이 주기는 설정 값으로 변경이 가능합니다. Druid coordinator는 실행될 때마다 작업 전에 클러스터의 현재 상태를 확인합니다. broker, historical node와 마찬가지로 현재 클러스터 정보를 알기 위해 zookeeper 클러스터에 대한 연결을 유지합니다.
Druid coordinator node는 주로 세그먼트 관리와 분배 역할을 수행합니다. 더 상세하게 말하면, 코디네이터 노드는 구성에 따라 (based on configurations) 세그먼트를 로드하거나 drop하기 위해 historical nodes와 커뮤니케이션 합니다.
-> historical 노드 데이터의 관리 및 분산을 담당합니다.
- Druid coordinator는 새로운 세그먼트들을 로드하고, 오래된 세그먼트를 drop하며, 세그먼트 복제 관리 및 세그먼트 로드 밸런싱을 담당합니다.
- Druid coordinator는 주기적으로 실행되며 각각의 수행 사이의 시간은 설정 파라미터로 변경 가능합니다.
- Druid coordinator는 실행될 때마다 적절한 action을 결정하기 전에 클러스터의 현재 상태를 체크합니다.
broker, historical nodes와 비슷하게 Druid coordinator는 현재 클러스터의 정보를 얻기 위해 Zookeeper 클러스터에 대한 연결을 유지합니다.
또한, coordinator는 사용 가능한 세그먼트와 rules 정보가 있는 데이터베이스에 대한 연결을 유지합니다. (Coordinator는 MySQL서버에 접속합니다.)
사용 가능한 세그먼트는 세그먼트 테이블에 저장되고 클러스터에 로드되어야 하는 모든 세그먼트가 나열됩니다. Rule은 rule 테이블에 저장되며 세그먼트를 처리하는 방법을 나타냅니다.
할당되지 않은 세그먼트를 historical nodes에서 처리하기 전에 각 계층에서 사용 가능한 historical nodes를 용량별로 정렬합니다. 이때, 최소 용량 서버는 가장 높은 우선 순위를 가집니다.
할당되지 않은 세그먼트는 항상 최소 용량 노드에 할당되어 노드 간 균형 수준을 유지합니다. coordinator는 새로운 세그먼트를 할당할 때 historical nodes와 직접 통신하지 않으며, 대신 historical 노드의 로드 큐 경로에 새로운 세그먼트에 대한 임시 정보를 저장합니다. 이 요청이 표시되면 historical 노드가 세그먼트를 load하고 서비스를 시작합니다.
더 자세한 내용은 링크 참고
4. Indexing Service
Druid indexing service는 인덱싱 관련 작업을 실행하는 고가용성 분산 서비스입니다. (high-available)
Indexing tasks는 Druid segments를 생성하거나 삭제(destroy) 합니다.
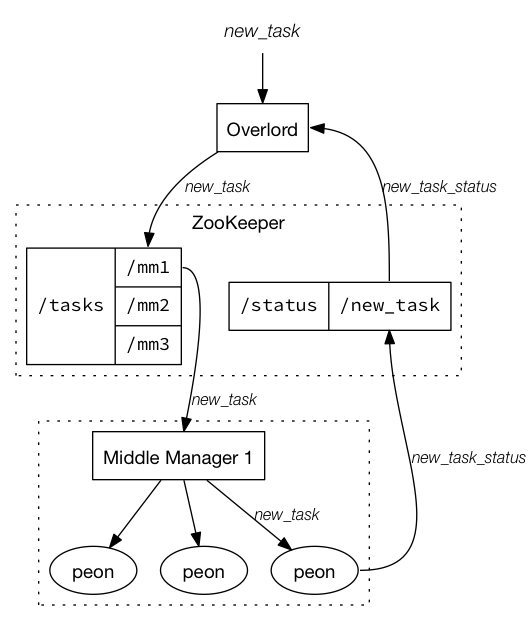
인덱싱 서비스는 세 가지 주요 components로 구성됩니다.
- Peon : 단일 task 실행
- Middle Manager : peon을 관리하는 미들매니저
- Overlord : MM(Middle manager)에 할당된 작업을 관리하는 오버로드
Overloads와 MiddleManager는 동일한 프로세스 또는 다른 프로세스에서 실행될 수 있지만, MiddleManager와 Peon은 항상 동일한 프로세스에서 실행되어야 합니다.
4.1 Overload
Overload Node는 태스크 수락, 태스크 분배 조정, 태스크 주변 잠금 생성(creating locks around tasks) 및 호출자에게 상태를 반환하는 역할을 합니다. 즉, 데이터 수집 workload 할당을 컨트롤합니다.
* workload : A workload is the amount of computing resources and time it takes to complete a task or generate an outcome.
* task : middle manager에서 실행되며 항상 단일 데이터 소스에서 작동합니다.
task에는 여러 유형이 있습니다. segment creation tasks, compaction tasks, segment merging tasks,...
자세한 내용은 링크를 참고해주세요.
오버로드는 로컬 또는 원격(기본값은 로컬)의 두 가지 모드 중 하나로 실행되도록 구성할 수 있습니다.
로컬 모드: 오버로드는 tasks를 실행할 peons를 생성하는 역할도 수행합니다. 로컬 모드에서 오버로드를 실행할 때는 모든 MiddleManager 및 Peon 구성도 제공해야 합니다. 로컬 모드는 일반적으로 단순 워크플로우에 사용됩니다.
원격 모드: Overload와 MiddleManager는 별도의 프로세스에서 실행되며 각각 다른 서버에서 실행할 수 있습니다. 인덱싱 서비스를 모든 Druid 인덱싱에 대한 단일 endpoint로 사용하려는 경우 이 모드를 사용하는 것이 좋습니다.
- Overload console
오버로드 콘솔을 사용하여 보류 중인 작업, 실행 중인 작업, 사용 가능한 작업자, 최신 작업자 생성 및 종료를 볼 수 있습니다.
http://<OVERLORD_IP>:<port>/console.html
4.2 MiddleManager
MiddleManager(중간 관리자) node는 제출된 task를 실행하는 worker node입니다. MiddleManager는 별도의 JVM에서 실행되는 peons(사용자)에게 작업을 전달합니다. 작업을 위한 별도의 JVM이 있는 이유는 리소스 및 로그 분리를 위해서입니다. 각 Peon(사용자)은 한 번에 하나의 task만 실행할 수 있지만 MiddleManager는 여러 peons를 가질 수 있습니다.
4.3 Peons
Peons run a single task in a single JVM. MiddleManager는 task를 실행하기 위해 peon을 생성합니다. peon은 테스트 목적을 제외하고는 스스로 운영하는 경우가 거의 없어야 합니다.
5. Dependencies
5.1 Metadata Storage(MySQL)
Druid는 메타데이터 저장소를 외부 종속성에 의존합니다. Druid는 메타데이터 저장소를 사용하여 시스템에 대한 다양한 메타데이터를 저장하지만 실제 데이터는 저장하지 않습니다. 메타데이터 저장소는 드루이드 클러스터가 작동하는 데 필수적인 모든 메타데이터를 유지합니다. Derby는 Druid의 기본 메타데이터 스토어지만 운영에는 적합하지 않습니다. MySQL이나 PostgreSQL이 더 안정적이며 운영에 적합합니다.
메타데이터 저장소에는 다음 내용들이 포함됩니다.
- Segments records
- Rule records
- Configuration records
- Task-relasted tables
- Audit records
5.2 Zookeeper
Apache Druid는 현재 클러스터 상태를 관리하기 위해 Apache ZooKeeper(ZK)를 사용합니다.
분산 애플리케이션을 위한 코디네이션 시스템으로 분산 애플리케이션이 안정적인 서비스를 할 수 있도록 분산되어 있는 각 애플리케이션의 정보를 중앙에 집중시킵니다.
6. 추가적인 내용
Router
TB 범위의 Druid Cluster가 있는 경우에는 router node가 필요합니다. router node를 사용해서 쿼리를 다른 broker node로 라우팅할 수 있습니다. 기본적으로 브로커는 셋업된 rule을 기반으로 쿼리를 라우팅합니다.
예를 들어, 최근 1개월 데이터를 핫 클러스터에 로드한 경우 최근 한달 내의 데이터가 포함된 쿼리는 전용 브로커 집합으로 라우팅할 수 있습니다. 이 범위를 벗어나는 쿼리는 다른 브로커 집합으로 라우팅됩니다. 이 설정은 더 중요한 데이터에 대한 쿼리가 덜 중요한 데이터 쿼리에 영향을 받지 않도록 쿼리 격리를 제공합니다.
참고)
Druid와 Timeseries DB(TSDB)와의 차이점?
https://imply.io/blog/apache-druid-vs-time-series-databases/
대부분의 TSDB는 서버 및 장치에서 메트릭을 수집하고 집계하도록 설계되었습니다. 메트릭은 일련의 타임스탬프, 태그 또는 속성 및 숫자입니다. TSDB는 일반적으로 각 메트릭 시리즈(series)를 저장하고, 각 series를 분할/공유하며, 숫자를 집계하는 쿼리 기능을 제공합니다. TSDB는 사용 사례가 단순히 숫자/카운터를 집계하는 것이고 각 series에 대해 복잡한 분석이 필요하지 않은 경우에 사용됩니다.
* 참고 : TSDB의 series는 RDB의 "Set of index entries"와 같습니다.
반면에 Druid는 데이터 웨어하우스에 기반했기 때문에 일반적인 TSDB보다 복잡한 쿼리 분석을 더 잘 수행할 수 있습니다.
Druid는 실시간 기반 파티셔닝 및 빠른 집계와 같은 TSDB의 아키텍처 뿐 아니라 검색 시스템 및 데이터 웨어하우스의 아이디어를 포함하여 모든 유형의 event-driven(이벤트 중심) 데이터에 적합한 실시간 분석 데이터베이스입니다.
Druid는 기본적으로 OLAP 엔진이지만, 현대적인 event-driven 아키텍처를 위해 설계되었습니다.
요약하자면, Druid는 여러 동시 사용자가 많은 데이터를 그룹화하고 필터링해야 하는 대규모 데이터세트에서 좋은 성능을 가집니다.
References
https://druid.apache.org/docs/latest/design/indexing-service.html
https://druid.apache.org/docs/0.13.0-incubating/design/
https://blog.voidmainvoid.net/440
https://metatron-discovery-docs.readthedocs.io/ko/latest/discovery/part01/druid_nodes.html
'데이터 엔지니어링' 카테고리의 다른 글
| Ansible Roles 사용 방법, 공식 문서 (0) | 2023.03.19 |
|---|---|
| Ansible Inventory와 variables 설정 방법 (0) | 2023.03.16 |
| Elasticsearch search_after vs scroll API(cursor) (3) | 2022.10.08 |
| Kafka exactly-once delivery 지원 (0) | 2022.09.03 |
| Zookeeper ZNode란 무엇인가? (0) | 2022.08.30 |




댓글